이 글은 포스텍 박찬익 교수님의 CSED312 운영체제 수업의 강의 내용과 자료를 기반으로 하고 있습니다.
이제 학기가 얼마 남지 않았다.
벌써 3학년 2학기의 끝이라니, 별로 한 것도 없는데 시간이 훅훅 간다.
한편으론 아직 1년이나 더 남았다는 사실이 참 슬프기도 하다.
문제는 졸업해도 대학원을 가야 한다는 것이다 아..
음.. 여하튼 이번 File system chapter는 정말 글을 쓰기가 어려웠다.
Implementation part에 있어야 할게 나오질 않나, 교과서에 없는 내용이 뜬금없는 위치에 나오질 않나, 전체적인 순서도 이상했다.
흐름이 없으니 글이 매끄럽게 써지지 않았고, 몇 번이나 고쳐야 했다.
유독 OS글을 쓸 때마다 매번 이런 하소연을 하는 것 같다 ㅋㅋ
이 글을 볼 후배님들은 이 글을 읽음으로써 고생을 적게 할 수 있길 바란다 ㅎ
OS는 pintos에 고통받는 것 하나만으로도 충분하다 ㅋㅋㅋㅋ
아 참고로 pintos는 이번 방학 때 간단한 공략집을 올릴 예정이다.
여러가지 세팅이라던가, 기초적으로 알아야 할 지식에 대해 포스팅할 예정이다.
개인적으로 Pintos에 너무 고통을 받았었기 때문에, 후배님들은 이런거에 시달리지 말고 행복한 학기를 살라는 마음에서 포스팅한다 ㅎ
Overview
이번 포스트에서는 File System Abstraction과 API에 대해서 배운다.
PPT의 순서와 많이 다르니 주의하자!
1. File Concept
컴퓨터는 자기 테이프, SDD, HDD 등 많은 storage media에 데이터를 담고 있다.
OS는 이런 데이터들을 좀 더 편하게 다루기 위해, uniform logical view of stored information을 제공한다.
다시 말해 OS는 higer-level abstraction from underlying physical storage device to logical storage unit, file을 제공한다.
이로부터 얻어지는 File의 정확한 정의는 다음과 같다.
A file is a named collection of related information that is recorded on secondary storage
여기서 secondary storage는 주로 nonvolatile이기 때문에 system reboot를 해도 데이터가 보존된다.
한편 File의 정보는 두가지로 나뉜다. Metadata와 data가 그것이다.
-
File Metadata
A file’s metadata is information about file that is understood and managed by the OS
간단히 데이터에 대한 데이터, 내지는 파일에 대한 데이터라고 생각하면 된다.
예를 들어 파일 사이즈, 최종 수정 시간, 생성한 사람 등등이 있다.
-
File Data
A file’s data can ve whatever information a user or application puts in it.
간단히 데이터 그 자체라고 생각하면 된다.
데이터 타입에는 numeric, alphabetic, alphanumeric 혹은 binary 정도가 있다.
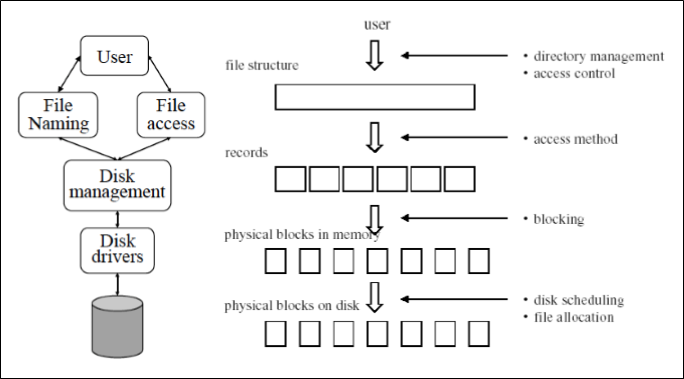
File system 관점에서 file’s data란 an array of untypes bytes, 좀 더 근본적으론 a sequence of physical block에 불과하다.
그러나 application 관점에서는 file’s data를 type bytes, 즉 특정한 포맷으로 데이터를 저장할 수 있는 record로 간주한다.
마지막으로 user 관점에서는 persistent data structure로써 file’s data를 바라보게 된다.
이 관점들은 어떻게 file이 physical storage device를 abstaction 했는지를 알려준다.
이 Abstraction으로 인해 user level과 system level에서의 file 접근 방법이 사뭇 달라지게 된다.
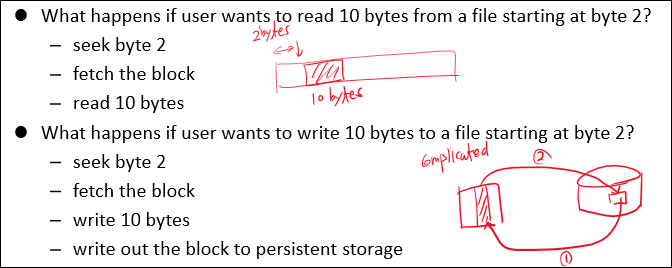
보다시피, user level에서는 bytes 단위로 명령을 내리지만, 실제로는 block 단위로 명령을 수행하게 된다.
곧, file system이란 file metadata 및 data와 관련된 여러 기능들을 담당하는 SW라 할 수 있겠다.
좀 더 구체적으로는 아래의 기능들을 담당한다.
- Creating, destroying, reading, writing, modifying, moving files
- Controlling access to files
- Management of resources used by files
File Attributes
File Metadata란 곧 file attributes를 말한다.
구체적으로 어떤 attributes가 있는지 알아보자.
- Name
The symbolic file name is the only information kept in humanreadable form.
- Identifier
This unique tag, usually a number, identifies the file within the file system; it is the non-human-readable name for the file
- Type
This information is needed for systems that support different types of files.
- Location
This information is a pointer to a device and to the location of the file on that device
- Size
The current size of the file (in bytes, words, or blocks) and possibly the maximum allowed size are included in this attribute
- Protection
Access-control information determines who can do reading,
writing, executing, and so on.
- Time, date, and user identification
This information may be kept for creation, last modification, and last use. These data can be useful for protection, security, and usage monitoring.
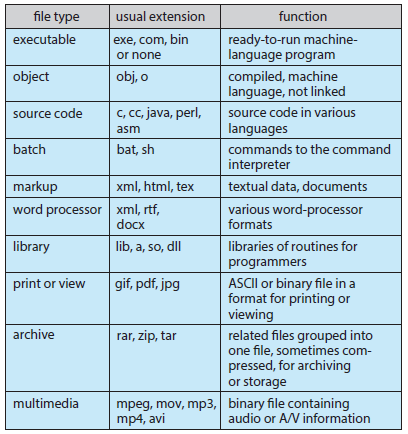
File Types
File system을 디자인 할 때 아주 중요한 것 중 하나는 OS가 file type을 인식하고 이를 지원할 수 있도록 하는 것이다.
File type을 구현하는 가장 흔히 쓰이는 방법은 file name에 file type을 포함시키는 것이다.
File name은 ‘.’ 을 기준으로 앞은 name, 뒤는 extension이 된다.
예를 들어 hello.cpp 에서 hello는 name, cpp는 extension이다.
OS는 이 extension을 통해 file type을 판단하고, 그에 맞는 적절한 동작을 수행한다.
일반적으로 OS가 지원하는 file types는 다음과 같다.
File Structures
File type은 file internal structure을 표시하는데 쓰이기도 한다.
File structure는 그 파일을 읽어들일 프로그램과의 협약이라 할 수 있다.
OS의 경우도 마찬가지이다.
예를 들어 executable file의 경우, OS가 instruction의 위치와 로드할 데이터를 구분할 수 있는 특정 구조를 가져야만 한다.
여기서 질문.
Supporting multiple file structures by OS is OK?
답: NO!
이 경우, OS의 크기가 지나치케 커진다.
예를 들어 5개의 다른 structure를 지원하려면 OS는 5개의 다른 코드를 짜야만 한다.
대신, minimum number of file structure만 지원하고 나머지는 application에게 맡기는 것이 훨씬 효율적이다.
2. Directory and Disk Structure
이제 file을 어떻게 저장하는지 알아보자.
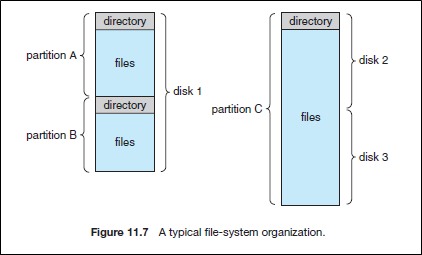
Storage device는 그 전체가 file system을 저장하는데 쓰일 수도 있지만 finer-grained control을 위해 하나 혹은 그 이상의 partitions로 나눠질 수 있다.
이 Partition는 file system로 쓸 수도 있고, swap space 로 쓸 수도 있고, unformatted (raw) disk로 놔둘 수도 있다.
만약 partition에 file system이 들어간다면, 이를 volume이라고 부른다.
Volume은 subset of device, whole device, 혹은 multiple deivce linked together (그림에서 오른쪽) 중 하나의 형태로 나타난다.
한편 volume은 반드시 자신이 갖고있는 file system에 대한 정보를 담고 있어야 한다.
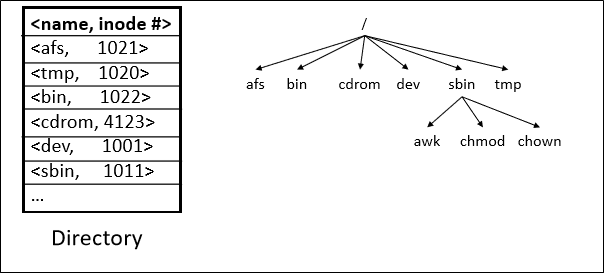
이 정보가 담겨있는 곳이 바로 device directory이다.
Device directory는 각 파일에 대한 file attributes를 저장하고 있다.
Storage Structure
앞서 보았듯, 한 컴퓨터는 여러가지 형태의 file system을 가질 수 있다.
예를 들어, Solaris는 아래의 file system으로 구성되어 있다.
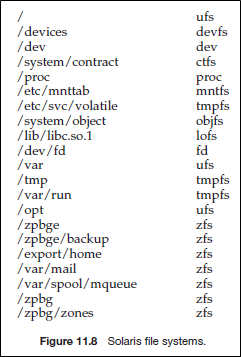
- tmpfs
“temporary” file system that is created in volatile main memory and has its contents erased if the system reboots or crashes
- objfs
“virtual” file system (essentially an interface to the kernel that looks like a file system) that gives debuggers access to kernel symbols
- ctfs
a virtual file system that maintains “contract” information to manage which processes start when the system boots and must continue to run during operation
- lofs
a “loop back” file system that allows one file system to be accessed in place of another one
- procfs
a virtual file system that presents information on all processes as a file system
- ufs, zfs
general-purpose file systems
우리가 다룰 것은 이중 general-purpose file systems 이다.
Directory
앞서 directory란 각 파일에 대한 file attributes를 담고 있는 공간이라고 했다.
좀 더 구체적으로 정의하자면 아래와 같다.
A symbol table that translates file names into their directory entries
이 관점에서 보았을 때, directory는 아래의 기능을 지원해야 할 것이다.
- insert entry
- delete entry
- search for named entry
- list all the entries in the directory
이 사실을 염두에 두고, directory를 구현하는 몇 가지 방법들에 대해 알아보자.
Single-Level Directory
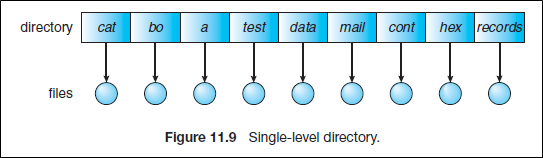
A single directory for all users
- 단점
- Naming problem
파일의 숫자가 늘어나고 시스템이 여러 유저에 의해 사용되면 모든 파일들은 같은 디렉토리에 있으므로 unique name을 가져야 한다. 파일이 엄청 늘어나면 이름을 기억하기도 힘들어 질 것이다.
- Grouping problem
Grouping이 지원이 안된다.
Two-Level Directory
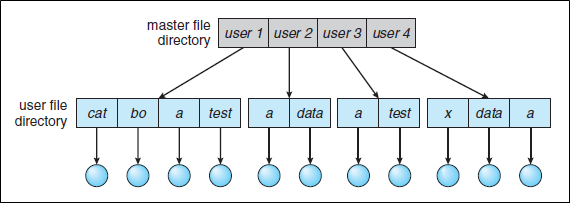
Separate directory for each user
- 장점
- 단점
- No grouping capability
여전히 Grouping이 지원이 안된다.
- Isolation
한 사용자를 다른 사용자로부터 고립시킨다. 이것은 장점이 될 수도 있지만 태스크를 공유하고 싶을 때는 단점이 된다.
Tree-Structured Directory
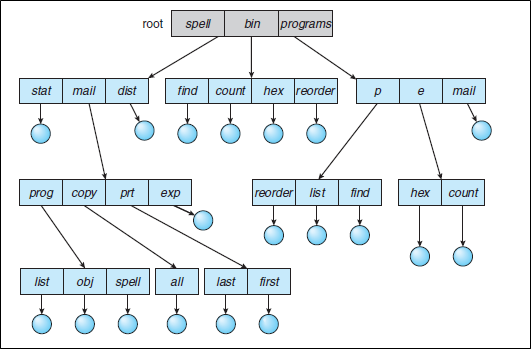
Extend the directory structure to a tree of arbitrary height
- 장점
-
Efficent Search
-
Grouping capability
Subdirectory를 이용한 grouping이 지원된다.
- 단점
- No co-pointing
하나의 파일이 하나만 가리키므로 하나의 파일을 여러개가 동시에 접근 불가능
- 새로운 개념
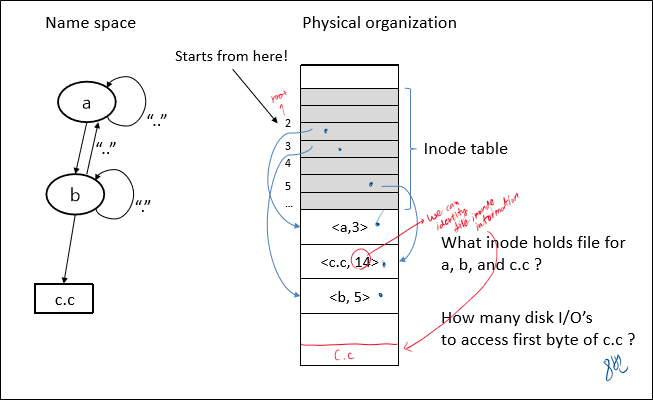
- Subdirectory
하위 directory. Directory considered as file!
- Current directory (a.k.a working directory)
- Path name
- Absolute
begins at the root and follows a path down to the specified file, giving the directory names on the path
- ex) root/spell/mail/prt/first
- Relative
defines a path from the current directory
- Speical path name
- ’.’ : working directory
- ’..’ : parent directory
- 논의
- Deleting a directory?
디렉토리가 비어있으면 그냥 지우면 되지만 안비어 있으면 2가지중 하나를 선택해야 한다. 첫째는 지우지 못하도록 하는 것이고 둘째는 옵션을 주는 것이다. 내용들을 날리거나 지우지 않거나 선택하게 한다. 두번째가 편리하지만 위험할 수 있다.
Acyclic-Graph Directory
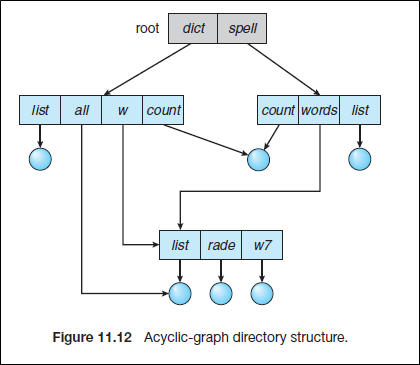
- 장점
- Allow co-pointing
Tree-Structured에선 지원하지 않던 서로 다른 이름이 같은 파일 pointing 가능
- 단점
- Overhead when traversing
똑같은 파일을 두 번 탐색할 가능성
- 새로운 개념
- New directory entry type
- Link
Another name to an existing file
- Resolve the link
Follow pointer to locate the file
- 논의
- Dangling pointer
하나의 파일을 삭제하였을 때 그 파일을 공유하고 있던 다른 파일은 잘못된 pointer를 가지는 현상
- Solution: Reference count를 세서, count가 0이 될 때만 삭제되도록 함
Hard Link
추천 블로그
Link에 대한 개념을 좀 더 심화시켜보자.
Hard Link란, a directory mapping from a file name directly to an underlying file을 말한다.
곧, 우리가 파일을 만들 때(e.g., /a/b) 생기는 directory entry는 새로운 파일과의 hard link가 된다.
만약 같은 파일에 link()를 써서 hard link를 하나 더 만든다는 것은(e.g. link(“/a/b”, “/c/d”)), 같은 파일에 다른 두 개의 이름을 주는 것이 된다.
그리고 만약 unlink(“/a/b”)를 한다면, “/c/d”가 해당 파일을 가리키는 유일한 valid name으로 남는다.
거기에 이어 unlink(“/c/d”)를 해서 모든 hard link가 사라지면(reference count == 0) file이 삭제된다.
Soft Link
Soft link or Symbolic link란, directory mappings from a file name to another file name을 말한다.
Soft link로 원래 file을 얻어내는 과정은 이렇다.
-
Soft link로 파일을 연다.
-
파일로부터 target name을 구해낸다.
-
Target name을 통해 target file을 연다.
Soft link는 file이 아니라, file 이름을 가리키는 link다.
실제로 inode를 찍어보면 hard link의 inode와 soft link의 inode는 다르다.
따라서 hard link reference count에 속하지 않으므로 모든 hard link가 제거되면 설령 soft link가 남아있더라도 파일은 삭제되며, soft link는 유효하지 않은 link가 된다.
예를 들어 만약 “/a/b”를 만들고, “/a/b”로의 soft link “/c/d”를 만든 다음 unlink(“/a/b”)를 한다면 open(“/c/d”)는 실패하게 된다.
일종의 바로가기라고 생각하면 이해하기 쉽다.
3. File System APIs
기초적인 file system의 구조에 대해선 알아봤고, 이제 file system이 제공해야 하는 기능에 대해 구체적으로 알아보자.
File system에서 제공하는 기능, 즉 API를 몇가지 중요한 것만 추려보면 다음과 같다.
- create, link, unlink, mkdir, rmdir, rename
- open, close, read, write, seek
- fsync
- Force modification in cache (volatile memory) to disk
- stat
create, link, unlink는 간단히 알아보았고, 이번 챕터에선 open, read, write에 대해 알아보자.
open()
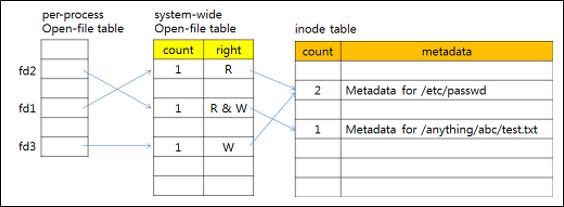
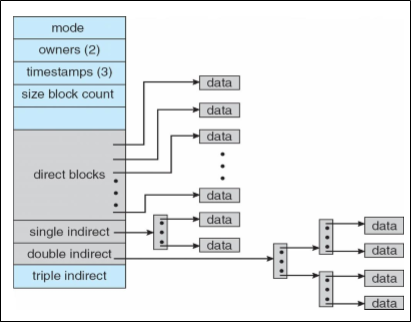
open()을 이해하기 위해선 in-memory file data structure에 대해 이해해야 한다.
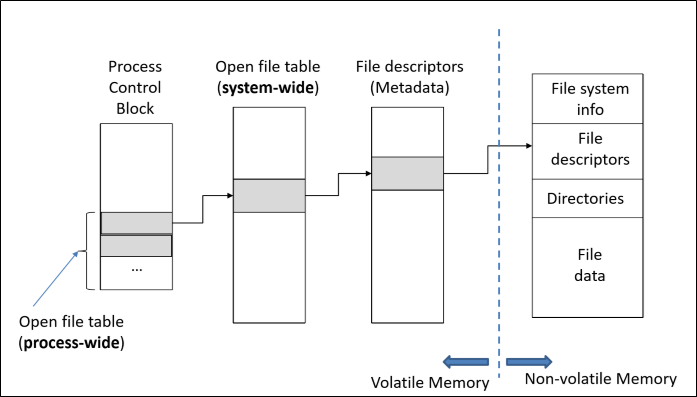
File system은 Disk, non-volatile memory에는 우측의 구조로 저장되어 있다.
빠른 파일 접근을 위해, 이 중 file descriptor, 즉 file metadata part를 메모리에 불러 들이는 것이 목적이다.
그런데 이 메타데이터를 바로 process가 바로 쓰는 것이 아니라, 중간에 system wide table을 하나 거쳐야 한다.
System-wide open file table은 process간에 공유하는 table로써, file pos, reference count 등 파일 접근에 관한 데이터를 담고 있다.
한편 process-wide open file table은 process 고유의 table로, 현재 process가 어떤 file을 열고 있는지 표시하고 각각의 entry(file)에 file descriptor number를 부여하는 역할을 한다.
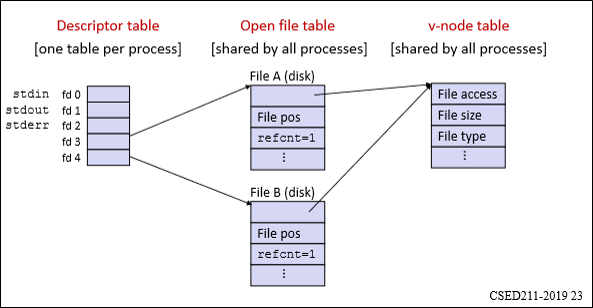
system-wide table이 왜 필요한지 살짝 감이 안 잡힐 수 있다.
예를 들어 Process가 open을 두 번 불렀을 때를 상정해보자.
만약 system-wide table이 없다면 각각의 호출에서 얻은 descriptor는 아무 차이가 없게 되고, 이는 의미없는 동작이 되어버린다.
반대로 system-wide table을 도입한다면 같은 파일을 사용하지만 서로 독립적으로 동작하는 descriptor를 얻을 수 있다.
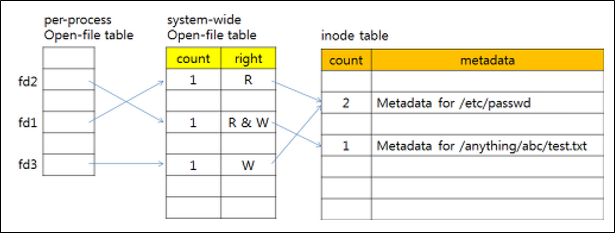
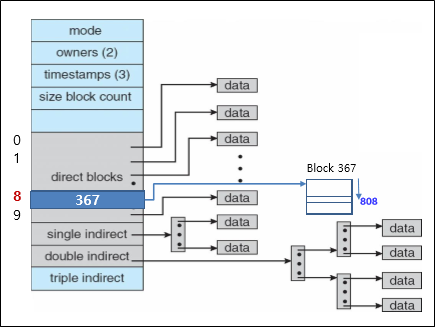
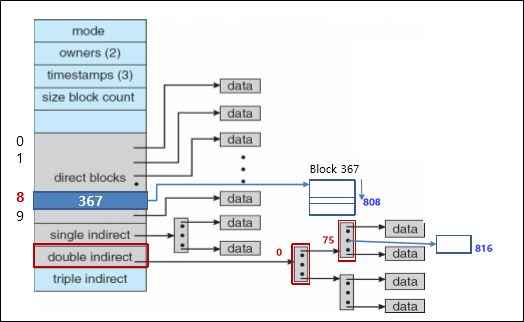
위는 UNIX 에서의 in-memory structure이다. (Inode index는 file에 주어지는 고유 번호이다)
자 이제 open()의 동작을 구체적으로 알아보자.
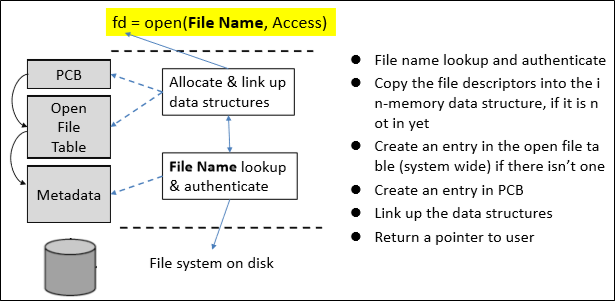
아마 in-memory data structure을 제대로 이해했다면 굉장히 쉬울 것이다.
그냥 각 table에 entry를 만들어줄 뿐이다.
read()
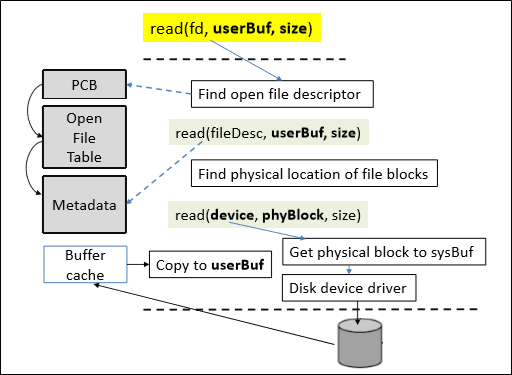
흐름만 알면 쉽다.
fd가 주어지면, Process-wide open file table을 조회하여 system-wide table entry를 얻어낸다.
여기서 한 단계 더 타서 file metadata를 얻어내어, user to file system translation(desc to device, buf to block)을 해준다.
디스크에서 읽어들인 값은 cache를 지나 최종적으로 userBuf에 들어가게 된다.
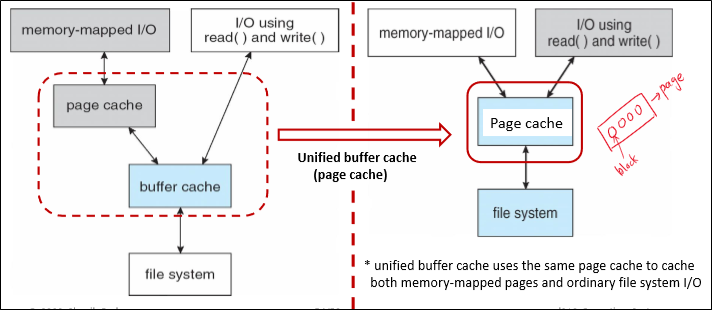
Buffer cache에 대해서는 다음 시간에 배울 것이고, 지금은 그냥 디스크와 메모리 사이에서 전달되는 데이터를 캐시하는 공간으로 생각하면 된다.
write()
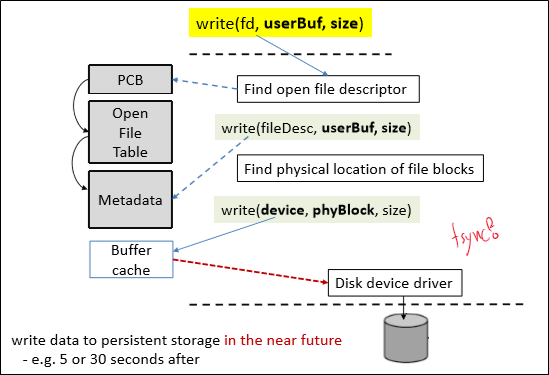
read()와 전혀 다를 바가 없다.
다만 위에서는 디스크에서 들어오는 데이터를 캐시하는 용도였던 buffer cache가 지금은 write buffer로써 역할을 하는 것만 기억하면 된다.
4. File System Mounting
File system의 구조와 동작에 대해서 알아보았다.
이제는 file system을 어떻게 로드하는지 알아볼 차례이다.
File system은 그냥 디스크에 있다고 적용되는게 아니라, os에 mount를 해야 한다.
사용하고 싶은 파일을 소유한 파일 시스템을 특정한 directory(a.k.a mount point)에 mount하면 그 때부터 그 파일을 사용 가능한 것이다.
일반적으로 mount point는 비어있는 directory이다.
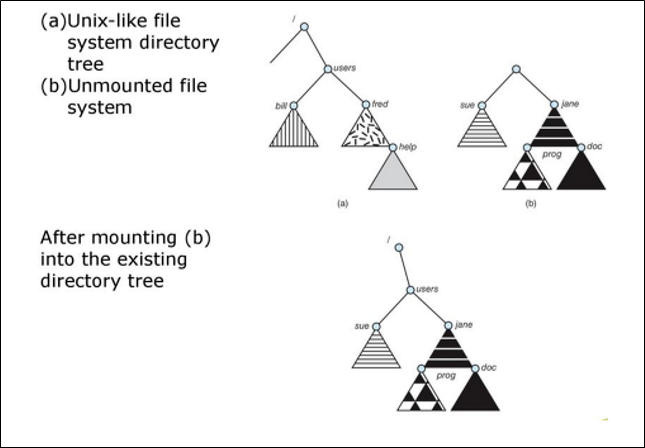
위는 간단한 예시이다.
(a)의 경우, 우측에 있는 /sue, /jane 등은 현재 접근 불가능하다.
(b)는 우측의 file system을 /users에 mounting 한 것이다. 이제야 비로소 /sue, /jane이 접근 가능하다.
5. File Sharing And Protection
딱히 교수님이 이 부분을 설명하시진 않았지만, 혹시 모르니 간단하게 짚고 넘어가려고 한다.
User간에 file sharing은 필수적인 기능이다.
그러나 항상 sharing은 protection issue를 낳는다.
Protection issue를 해결하기 위한 가장 기본적인 아이디어는 access permission을 제어하는 것이다.
다만 multi-user 환경이기 때문에, 좀 더 세밀한 권한 제어를 위해 file owner와 group이라는 개념을 도입한다.
Owner는 파일의 attributes를 바꿀 수 있고, 접근 권한을 부여할 수 있는 등 파일에 대한 최대한의 권한을 갖는 user를 말한다.
Group는 접근 권한을 공유하는 user 집합을 의미한다.
이 개념을 적용하면, 파일에의 접근 권한을 owner / group / public (other user)로 세분화 할 수 있다.

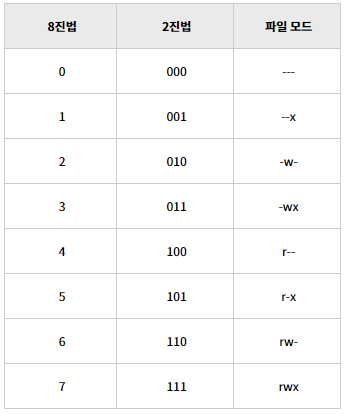
이때, UNIX에서는 접근 권한을 3 bit 로 표현한다.
파일에 접근 권한을 지정하는 명령어는 chmod이다.
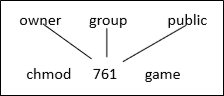
예를 들어 위의 명령어는 game 파일의 접근 권한을 owner는 rwx, group은 rw-, public은 –x 로 지정한다.
6. 참고자료
]]>